引言
师哥程序员交流群里,上次那位刚刚入门的兄弟,在看完我为他写的《你真的了解,JAVA中equals方法背后的细节吗?》之后。立马就来告诉我喜讯,他按着师哥的步骤,成功地写出漂亮,正确,完美的equals方法。但俗话说,乐极生悲是有道理的,前话刚落三秒,就有了下面的对话。
兄弟:师哥,我又遇到问题了。。。
师哥:what!!!你怎么这么多问题,你是不是,就是喜欢看师哥,肝技术文章时帅气的模样? 兄弟:不是的,师哥,是真有问题。我把一个元素放进HashMap之后,但取不出来。
师哥:♩ ♪ ♫ ♬ ♭ ♮ ♯
师哥:上次说漏了equals的生死相依的兄弟hashcode。我现在去给你写文章,好了给你说。。。
分析
问题出现了,为了明白发生错误的根本原因。师哥就从事故现场开始,一步一步为大家剖析出那个唯一的真相。
事故现场
我们来看看,这兄弟发给我的这份,有错误的代码。
package wejias.com;
import java.util.HashMap;
import java.util.Map;
public class Student {
public int id; // 学号
public String name; // 学生姓名
@Override
public boolean equals(Object obj) {
if (this == obj) { return true; }
if (obj == null) { return false; }
if (getClass() != obj.getClass()) { return false; }
Student other = (Student) obj;
if(id != other.id) {
return false;
}
return true;
}
public static void main(String... args) {
Map<Student,Integer> studentScoreMap = new HashMap<Student,Integer>(2);
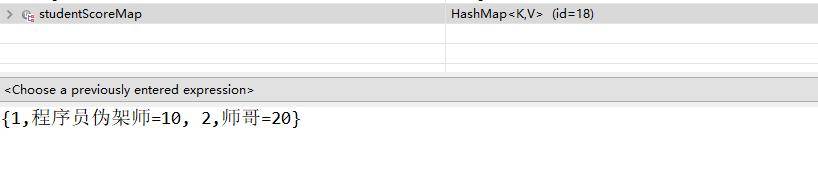
studentScoreMap.put(new Student(1, "师哥"), 10);
studentScoreMap.put(new Student(2, "程序员伪架师"), 20);
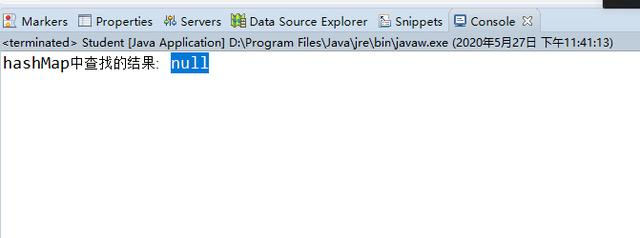
System.out.println("hashMap中查找的结果: "+studentScoreMap.get(new Student(1, "师哥")));
}
}师哥,一看这代码很漂亮呀,和我风格很近呀。。。(尴尬脸),但确实运行起来,就是找不到已经put进Map里面,那个“1,师哥”。
原因分析
难道是没有put成功???But,一测试,put是成功的。“1,师哥”还在的。 这是什么情况呢,放进去了,为什么取又不取出来呢?
2.源码大法。既然找不到原因,我们就去看这个Map的get方法,底层源码到底是如何实现的。
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}获取结点时,是将hash(key)和key两个参数,传入getNode方法。看来,我们还要去看getNode方法。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}这里我们,注意2个关键的地方。
if (first.hash == hash &&((k = first.key) == key || (key != null && key.equals(k)))) ................ if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
这两个地方,我们可以发现,都是先比较hash,如果hash不同,则不进行equals方法判断。那么上面的hash(key),又是怎么样的呢?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}哎,此处key.hashCode(),好像我们Student类,没有这个hashcode方法。。。
总结
因为,hashmap根据键提取元素时,首先比较 hashcode,然后是 equlas。上面Student类没有实现自己的hashcode方法。而父类Object类的hashcode是根据存储地址计算出来的。那么相同元素的,hashcode有可能不相等,从而导致了上面的问题。
解决
解决方案就是,为Student类在重写equals方法之后,再将hashcode进行重写即可。师哥之前说过,Object类中,所有可以重写方法,都有一定的约束,hashcode也不例外,它约束有以下面3个。
重写equals,必须重写hashcode。 如果equals为true的两个对象,hashcode也必须相等。 如果equals为false的两个对象,hashcode可以相等,也可以不相等。
针对最后一点,作为一个优秀程序员的师哥。需要告诉你的是,一个优秀的hashcode算法,必须尽量让不同元素的hashcode也不相同,以此降低hash冲突,提升效率。
重写hashcode的Tips
师哥为大家总结了以下几点,重写hashcode方法的Tips:
1.参与hashcode计算的字段,应该是equals中用到的字段;
2.equals方法没有用到字段,不需要参与hashcode的计算,减少计算量,提升效率;
3.针对不可变类(final class),可以将hash存为局部变量,从而只计算一次,提升效率。
示例
百说不如一练,下面师哥为上面的Student重写hashcode方法。你看完了,也赶快回去找找,你代码中有没有重写equals方法之后,没有重写hashcode的BUG吧。
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
return result;
} 









{kind=link}