背景
师哥最近想买部手机,前同事给了一个网站。说这个网站,每天价格,会有一定变化,时高时低的。
师哥一想,我只要每一天,去记录一下手机的价格,那么就可以用一个相对低一点的价格,买入手机了。
师哥是一个程序员,不可能真的每天去看一个购物网站(每天看购物网站的程序员,不是真程序员,除非是看机械键盘)。
那么,方法,就只有一个了。师哥,自己写一个程序。每天替我去看看这个网站,并记录下数据,再进行数据分析,在价格相对较低的情况,发封邮件通知我。
开码
开发流程
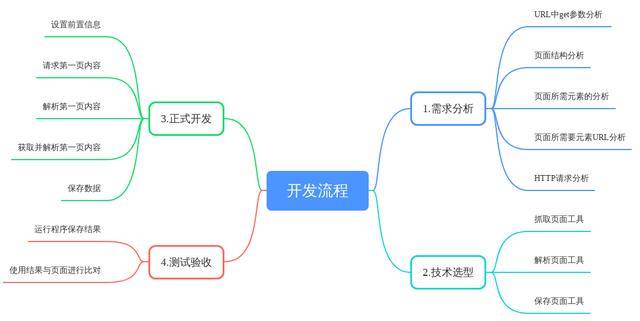
URL中GET参数分析
多点击几个相关页面,仔细观察变化的参数,并推测其意义及关联性。不变的参数,在开发中直接抄过来即可。页面结构分析 页面所需元素的分析
主要分析,所需信息的元素,在什么位置;其相关的css样式,id参数之类的。后续解析和提取数据时,需要用到这些参数。页面所需要URL分析
仔细观察,点击所需元素时,url或者http请求中,发生变化的参数。并找出这些参数来源,及相关性。HTTP请求分析
我是直接用chrome的F12,直接观察的。主要注意,http请求头,cookie等信息。
这里需要注意的是,有的网站,因为禁用了鼠标右键之类的原因。不方便直接观察和分析页面时,就需要用抓包工具,抓出请求时的参数。再直接编码使用这些抓到参数,将页面抓下来放到本地分析。
当完成这些分析时,其实爬虫工作就已经接近成功了。
需求分析
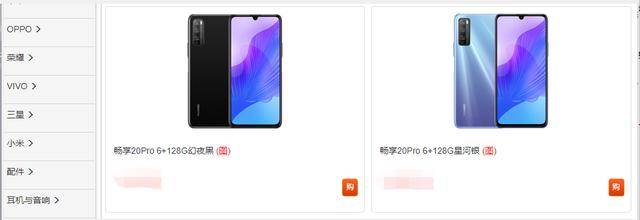
我们需要的就是将手机名称及价格保存下来。(下文中我将该网站的域名,使用{URL}代替)
URL:{URL}?pp=&km=华为.手机.畅享20系列7&network=&tykhgsdm=
我们通过观察分析,得出:
km参数是由手机的一级,二级,三级分类的名称,加上“.”号,组合而成。 HTTP请求时还有一个cookie:JSESSION:************** 左侧分类通过html.xpath("//a[contains(@onclick, 'javascript:kmjump')]"),进行提取 手机名称通过html.xpath("//a[contains(@href, 'goodsdetails.action?sptid=')]/h5/text()"),进行提取 手机价格通过html.xpath("//p[@class='pull-left']/text()"),进行提取
技术选型
数据存储
数据抽取出来,师哥现在只想存到execl中,就直接选中了POI。如果,是想存CSV呢,可以用superCSV。想存数据库的话,选择就比较多。可以使用原生JDBC,也可以mybatis,hibernate等ORM框架。
Jsoup or WebMagic
师哥,刚毕业工作时,公司安排一个类似的工作,让我每天去抓一个供应商的数据,然后入库。(这样可以省一个人,去干这个事。写完了,给了我2000奖金)那次,师哥用的JSOUP是,去解析和提取网页元素。
这次开始码代码之前,我想这么多年过去了,应该会有些更好用的工具。果然有很多新鲜玩意,最后决定这次尝试一下WebMagic。 在实际开发中,这两者差别并不是太大。
JSOUP
Jsoup中,其实也包含了HttpClient组件,可以直接获取网页。Jsoup.connect("xxx")方法返回一个Connection对象。通过Connection,可以执行get或者post来执行请求。执行请求之前,可以设置一些请求信息。比如:头信息,cookie,请求等待时间,代理等等来模拟浏览器的行为。 Jsoup比较厉害的地方,在于丰富的获取HTML元素的API。 可以使用DOM的方式来取得,例如:
getElementById(String id); //通过id来获取
getElementsByTag(String tagName); //通过标签名字来获取
getElementsByClass(String className); //通过类名来获取
getElementsByAttribute(String key); //通过属性名字来获取
getElementsByAttributeValue(String key, String value): //通过指定的属性名字,属性值来获取
getAllElements(); //获取所有元素
也可以通过,类似于css或jQuery的选择器来查找元素,例如:
Elements links = doc.select("a[href]"); //带有href属性的a元素
Elements pngs = doc.select("img[src$=.png]"); //扩展名为.png的图片
Element masthead = doc.select("div.masthead").first(); //class等于masthead的div标签
Elements resultLinks = doc.select("h3.r > a"); //在h3元素之后的a元素
除此之外,Jsoup还可以通过JsoupXPath方式寻找元素。
JsoupXPath补充小课堂:
JsoupXPath有4种寻找节点的方式:
1.绝对路径语法。就是以“/”开头,一级一级描述标签的层级路径,不可以跨层级。
"/父元素/子元素/孙元素/..."
String str = "/body/table/tbody/tr/td"; //绝对路径找节点
2.相对路径语法。已有JXNode节点对象的情况下,通过此节点再往下寻找此对象内的其他节点。
"./子元素/孙元素"
JXNode jxn = jxd.selNOne("/body/table/tbody");
List<JXNode> sel = jxn.sel("./tr");
3.全文搜索路径。在全局搜索对应的标签,不需要从根目录开始搜索。
"//元素" 全局搜索元素
"//元素/子元素或@元素属性" 全局搜索元素后的子路径中找子元素或属性
List<JXNode> jxNodes = jxd.selN("//td/input/@type"); //返回type属性节点对象
4.条件筛选语法。根据条件筛选过滤节点,前面部分为筛选的条件,后面可以加上操作的动作
//元素[@属性=value] 筛选属性为value值的节点对象
//元素[@属性=value]/text() 或者 //元素[@属性=value]/html() 获取元素为value值的标签体内容对象
List<JXNode> jxNodes = jxd.selN("//input[@type=checkbox]/html()");
Webmagic
Webmagic与Jsoup解析网页方面,差别并不大。只是Webmagic功能更多,更全。它覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。所以,使用webmagic之后,在多线程请求,循环抓取方面,以及去重等抓取流程上相关点,就会少操很多心。
码途要点
在要点,这个小节,就主要说一下,师哥在开发这个小Demo中,遇到的cookie问题。
如何获取和设置cookie
这段代码,师哥没用多久,就写完了。可是写完抓了几遍之后,就抓不到数据了。仔细检查后,师哥发现浏览器请求中有cookie,而我的代码中是没有的。
这个问题,在师哥刚毕业那会儿,想的办法实在是太low了。师哥那时候,是用swing画了个UI,让同事在浏览器中真实地登录一次,再把cookie复制到我画的UI上面。
这次,师哥找到了一个东西,能够稍微优雅一点,解决这个问题。
想要爬取的网站需要登录时,可以用Selenium模拟浏览器登录,获取cookie,设置到webMagic的site中。
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.48.0</version>
</dependency>
Selenium 3.0以上版本需要JDK8。模拟浏览器登录,需要浏览器驱动,我使用的是Chrome,驱动Chromedriver。 下载地址:http://chromedriver.storage.googleapis.com/index.html(注意版本对应关系)。
设置cookie相关代码:
public static void getCookie(String path) {
System.setProperty("webdriver.chrome.driver", path); // 注册驱动
WebDriver driver = new ChromeDriver();
driver.get("url?currentPage=1");// 打开网址
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 获取cookie信息
cookies = driver.manage().getCookies();
driver.close();
}
--------------------------
public Site getSite() {
// 将获取到的cookie信息添加到webmagic中
if(GetAllTypeHtml.cookies != null && !GetAllTypeHtml.cookies.isEmpty()) {
for (Cookie cookie : GetAllTypeHtml.cookies) {
site.addCookie(cookie.getName().toString(), cookie.getValue().toString());
}
}
return site;
}
结语
师哥这个工具,每天抓一次,所有手机的价格。然后就可以在降幅比较大的时候出手了。不过现在这个程序,只实现了前面抓取,存储数据。后面分析这块还有没有写,等后面有时间,有钱了,准备买手机的时候,就去补上。
另外,此次抓取数据,由于对方网页反扒意识还不够,所以比较容易。一般爬虫会遇到的数据加密,IP封禁等问题都没有遇到,所以没有实战。下次,希望有机会研究和学习一下,这几个问题。
这个Demo的所有代码,我已上传到Github上面。各位基友,可以去看看,提出意见修改修改。










{kind=link}